
Independent Case Study: Training Reinforcement Learning Agent to Test Marvel Snap CCG Deck Balance
Problem Statement
Designing and balancing card game decks is a time-consuming process that traditionally relies on expert heuristics and extensive playtesting. We address the opportunity to accelerate and deepen this process by building a headless, high‑throughput simulator of Marvel Snap in Unity, then applying Reinforcement Learning (RL) and self‑play to evaluate deck performance automatically.
Approach
We started with the simplest agents possible and then gradually increased the complexity of the agents and the sophistication of the training process.
- Heuristic Baselines: Implemented simple agents that play the highest‑power legal card to a random location, establishing unoptimized win‑rates for two decks (Kazoo vs. Odin On‑Reveal)
- Single‑Agent RL: Used PPO (ML‑Agents) to train one deck at a time against the heuristic opponent, with progressively richer observation vectors, demonstrating RL’s power to overcome deck‑structural disadvantages or amplify strengths.
- Self‑Play RL (Symmetric & Asymmetric): Leveraged ML‑Agents self‑play feature to train both agents under one policy (symmetric) and under two separate policies (asymmetric), closing the win‑rate gap and producing balanced, strategic play.
Implementation Details
Deck Comparison
Kazoo is a low-cost, flood-oriented deck that deploys cheap 1-cost cards en masse and amplifies their power through global ongoing buffs (Ka-Zar, Blue Marvel) and location-specific multipliers (Onslaught).
Odin On-Reveal, by contrast, is a mid-game combo deck built around on‑reveal triggers (e.g., White Tiger, Jessica Jones) and Odin’s ability to replay those triggers on turn 6, requiring careful timing and sequencing rather than sheer tempo.
Simulator Core
- Unity (headless mode) running hundreds of games in parallel. (DOTS was not used in this simulation)
- Data-driven via JSON configs for cards, decks, and effects
- Simulation Simplifications: no location effects implemented; no movement cards (e.g., Nightcrawler, Iron Fist) in simulation.
- Performance: combined simulation, inference, and model training throughput of ~5,000 cards played per second on a Mac Mini M4 (10‑core CPU, 10‑core GPU).
Agents
Heuristic (Scripted Bot): Selects highest‑power card and places it to random valid location.
Reinforcement Learning Agent (RL): PPO via Unity ML‑Agents
- Observations: turn, energy, hand (cost + power), board power/count, playable‑count, card embeddings.
- Actions: discrete pair (card index, location index).
- Rewards: +1 win, –1 loss.
- Neural network size: 768 units.
Training Regimes
- Single‑agent: RL only on one deck vs. heuristic opponent.
- Symmetric self‑play: Shared policy across both decks, different team IDs.
- Asymmetric self‑play: Two separate policies trained adversarially.
Hardware & Runtime
Consumer level inexpensive hardware was chosen intentionally.
Mac Mini M4 (10‑core CPU, 10‑core GPU).
Self‑play training (two agents) completes in ~1.5–3 hours depending on confidence interval.
Win-Rate Summary
| Agent Combination | Player 1 Win % | Player 2 Win % |
|---|---|---|
| Heuristic vs Heuristic | 71.42% | 28.58% |
| Heuristic Kazoo vs RL On-Reveal (minimal inputs) | 69.30% | 30.70% |
| Heuristic Kazoo vs RL On-Reveal (rich inputs & hyperparams tuning) | 34.13% | 65.87% |
| RL Kazoo vs Heuristic On-Reveal | 82.11% | 17.89% |
| Symmetric Self-Play RL (shared policy, different decks) | 58.47% | 41.53% |
| Asymmetric Self-Play RL (two policies, different decks) | 56.23% | 43.77% |
Insights
✔ A minimal-input RL agent can outperform the heuristic baseline. Even lightly trained models deliver strategic value under tight compute budgets, allowing small undertrained agents to provide meaningful gameplay insights.
✔ There is a large gap in win rate between the heuristic Odin On-Reveal deck (28.58%) and the tuned RL version (65.87%). It basically shows that RL version is able to find better strategies by utilizing more sofisticated combos. Under symmetric self-play, RL agents on both decks produce win-rate distributions more reflective of human gameplay. That behavior simulates how humans would find dominant strategies in gameplay and then capitilize on them.
✔ Learning curves provide invaluable insights into how quickly each deck can be mastered.
- The reward curves for both decks are shown in the graph below. Kazoo deck reward flattens much faster (Green). This indicates that the agent has nearly reached peak performance.
- This information is much easier to spot when the RL agent plays against the heuristic bot or in an asymmetrical self-play scenario (with separate policies).
- However there is still posibility to observe this statistic even in symmetrical self play scenario. For example thrugh ELO rating peaks.
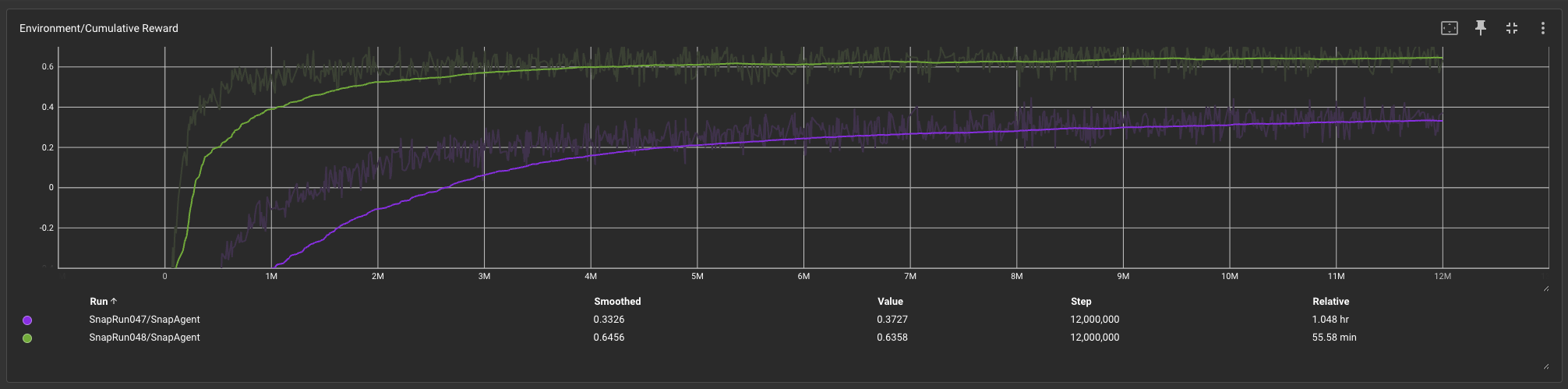
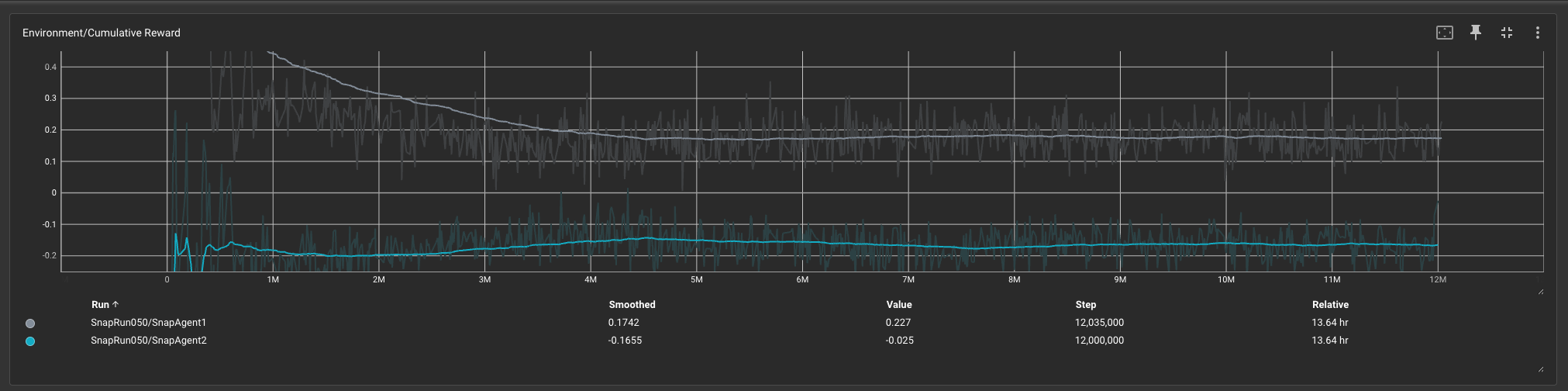
✔ Symmetric and asymmetric self‑play both yield similarly realistic win rates. Training a symmetric agent incurs less overhead since only one training routine runs, and forward and backward passes occur on a single network rather than two, significantly cutting training time.
Use in Production and Future Directions
Two main issues for CCG games are initial balance before release and the addition of new cards during the LiveOps phase.
- By running AI playtests on decks of various archetypes before release developers can be sure that meta-gameplay stays balanced and non of archetypes severely overpowers another. Without AI playtesting, achieving this coverage would require thousands of hours of human testing.
- For LiveOps projects, the addition of new cards often poses a risk of power creep, potentially making older cards and the existing meta obsolete. Playtesting with agents can help avoid unnecessary nerfs/buffs after card was release.
Scalable Production Paths:
- Per‑Deck Models: Train separate networks for each deck, discarding and retraining per test - ideal for rapid A/B testing.
- Universal Model: Train a single, large network capable of playing any deck - longer training but enables instant playtesting of new decks post‑training.
Future Improvements: Many additional observations (e.g., cards remaining in deck) remain untapped, offering further opportunities to improve a generic agent’s performance across all decks.
Services for CCG, Strategy & Puzzle
Cut Weeks Off Game Balancing with AI Playtesting
Reinforcement learning agents play thousands of matches, reveal balance issues, and measure deck complexity in hours, not weeks.
- ✔Lower Costs – Shorten production cycles, cut expenses.
- ✔Scalable agents tuned for CCG, turn-based, tactical & puzzle loops.
- ✔Data-Driven Balancing – Simulate strategies & fine-tune design with measurable insights.
Let's Discuss Your Project
Tell us about your project. We’ll reply within 1 business day.